
I was lucky enough that in relatively early time in my career I bet on NGINX as my default HTTP server and essentially never looked back. Sure enough, I started with using it as reverse-proxy in front of Apache, but once it matured enough and I felt confident it can be trusted with essentially any HTTP-related task, I switched entirely. It was a long time ago and NGINX has made some tremendous progress since then. While its adoption didn’t exceed Apache so far, it’s in the second place for quite some time now and growing in numbers each month. I was always fond of it being so lightweight and I preferred usage of FastCGI protocol instead of native/built-in one as it was the case with Apache at that time.
The caveat is that, while being Open Source application, there are some functionalities that are available only for the paying customers (NGINX Plus). I don’t mind this kind of business model. After all, this is a great application and I hope it will stay around for years to come and the only way to achieve that goal is to keep it sustainable, financially-wise. On the other hand, I’m not able to afford NGINX Plus subscription model (especially for private use-case like mine). Fortunately enough, there are some NGINX enthusiasts out there that are creating 3rd party modules for their favourite HTTP server. Quite a few of them.
Package all the things!
One of the requirements I had was to build proper Debian/Ubuntu packages. At first I was distributing these solely for my employer from within our internal repository. All the packages were properly signed and trusted internally etc. Going further though I realised there might be more people interested in at least some of that work, so I opened and published sources. All I’m really doing here is grabbing original sources of NGINX package from Ubuntu and adding static and dynamic modules where needed using official way of doing it. That’s all. On top of that, you can now head over to my NGINX PPA and grab debs for these modified NGINX packages with 3rd-party modules built-in or available dynamically. These packages are built on the Launchpadservers.
sudo add-apt-repository ppa:hadret/nginx
sudo apt-get update
Supported distributions are xenial (16.04 LTS) and bionic (18.04 LTS). Only stable version of NGINX is available. Should you spot/encounter any problems, be sure to create an issue ticket on the aforementioned GitHub page.
3rd Party Modules
As I mentioned earlier, there’s a lot of modules out there that can be enabled/build with NGINX. Obviously my list is opinionated and I figured I’m gonna need a place where I can lay down reasons for picking this and this or that. Here goes nothing.
Upsync
 weibocom
weibocomThis has to be one of the coolest modules ever made for NGINX period. Imagine having multiple frontend (HTTP) servers sharing a fleet of backend servers (let’s say PHP, Python, Node.js, whatever else). Now assume that all of the backend servers are registering in, for example, Consul using its built-in health check mechanism – wouldn’t it be great if you could simply point your NGINX servers to Consul to fetch information such as address, port, availability, weight etc. for each backend server? All that without having to reload NGINX on changes? Or using Consul or etcd as simple KV store for having this information, still all dynamic.
upstream test {
upsync 127.0.0.1:8500/v1/health/service/test upsync_timeout=6m upsync_interval=500ms upsync_type=consul_health strong_dependency=off;
upsync_dump_path /usr/local/nginx/conf/servers/servers_test.conf;
include /usr/local/nginx/conf/servers/servers_test.conf;
}
So regardless of whether you are using curl to add and remove backend servers from KV store of Consul/etcd, or whether you rely on consul_service(with or without health checks) – everything is fully automated, ultra fast and without the need to reload NGINX.
There’s not much out there that can even compare to it. We were running it on relatively high traffic website across multiple of frontends with few upstreams leveraging Consul as source for the backend fleet. Ability to simply mark any given backend server as down and have it balanced out everywhere in seconds (or milliseconds in fact) is an amazing feature. All seamless, no reload, no hassle, no maintenance overhead. The only two things I can think of that have roughly the same functionality are:
- DNS-Based Reconfiguration (with
zone+resolvecombo to make it fly) – but here you can’t specify differentweightfor each backend,max_failsor any other standard parameters. - API-Based Reconfiguration which requires you to expose NGINXs api and to roll out changes to each frontend separately (as opposed to each frontend querying single source of truth to fetch this information on their own, hands-off fashion).
And guess what – both of these are available only in the premium version of NGINX.
This module alone was one of the very reasons I decided on re-building NGINX. Module itself is a dynamic one in my build and resides in the package called libnginx-mod-http-upsync.
Caveats
Not everything is so great, though. Here are some things that bother me:
upsynccan work nicely with theupstream checkmodule (described in next section), but it requires forked version of it. It’s not a huge deal, but one more dependency to keep in mind when the upgrade time is coming.- Due to the way it’s working, this module requires
epollas a connection processing method. In practice this rules out pretty much any other operating system than Linux. I’m not saying it’s a bad thing, but it’s a bad thing.
There’s some more, but I’m gonna hold it off until VTS module.
Upstream Check
xiaokai-wangNGINX comes with built-in passive checks for servers defined in the upstream block. One can set fail_timeout and max_fails values in order for NGINX to automatically decide on whether the given backend machine is healthy or not. At first it may sound like a good enough solution, but imagine the case when some backend is active (no timeout, not raising number in max_fails) but not really healthy. How? Failed deployment, code mismatch (different version, missing files), newly provisioned host that has FastCGI up and running but no code yet available at all etc.
Fear not, that’s where health_check comes and saves the day! If you are willing to pay for the premium NGINX, that is.
OK, the real saving the day in our case comes from yet another awesome 3rd party module: upstream check. As I mentioned earlier while describing upsync, I’m using different fork located here. Changes are slight but necessary for these two to play together.
upstream cluster {
server 192.168.0.1:80;
server 192.168.0.2:80;
check interval=5000 rise=1 fall=3 timeout=4000;
#check interval=3000 rise=2 fall=5 timeout=1000 type=ssl_hello;
#check interval=3000 rise=2 fall=5 timeout=1000 type=http;
#check_http_send "HEAD / HTTP/1.0\r\n\r\n";
#check_http_expect_alive http_2xx http_3xx;
}
The upstream defined above will be checked every 5000 milliseconds with allowed timeout of 4000 milliseconds. If the timeout goes up for up to 3 consecutive active checks, given backend server is marked as down and NGINX will no longer push any traffic towards it. If the backend server comes back up it will be raised after one successful active check.
And that’s just the simplest example. One can define multitude of different active checks to ensure that the given backend servers are healthy, including (but not limited to) sending of HTTP request and expecting 2xx and/or 3xx as a valid answer etc.
On top of that this module allows you to check and show dynamically status of the backend servers and print it out in csv, json or html. Those statistics are not very deep, but it’s still impressive piece of work.
This module can’t be build dynamically as it has to patch different kinds of balancing modes for the upstreams. It comes precompiled with NGINX from my PPA.
VTS
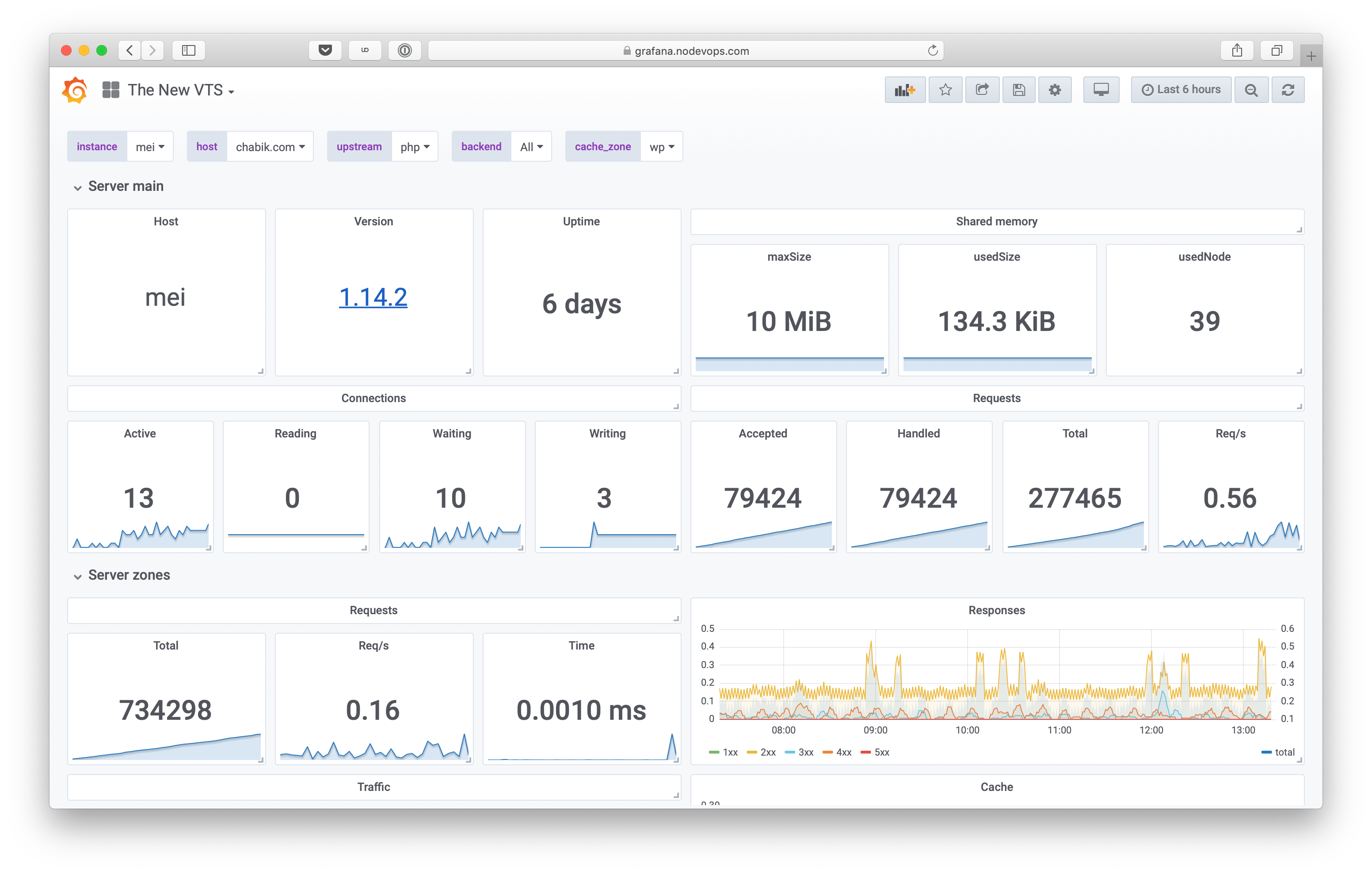
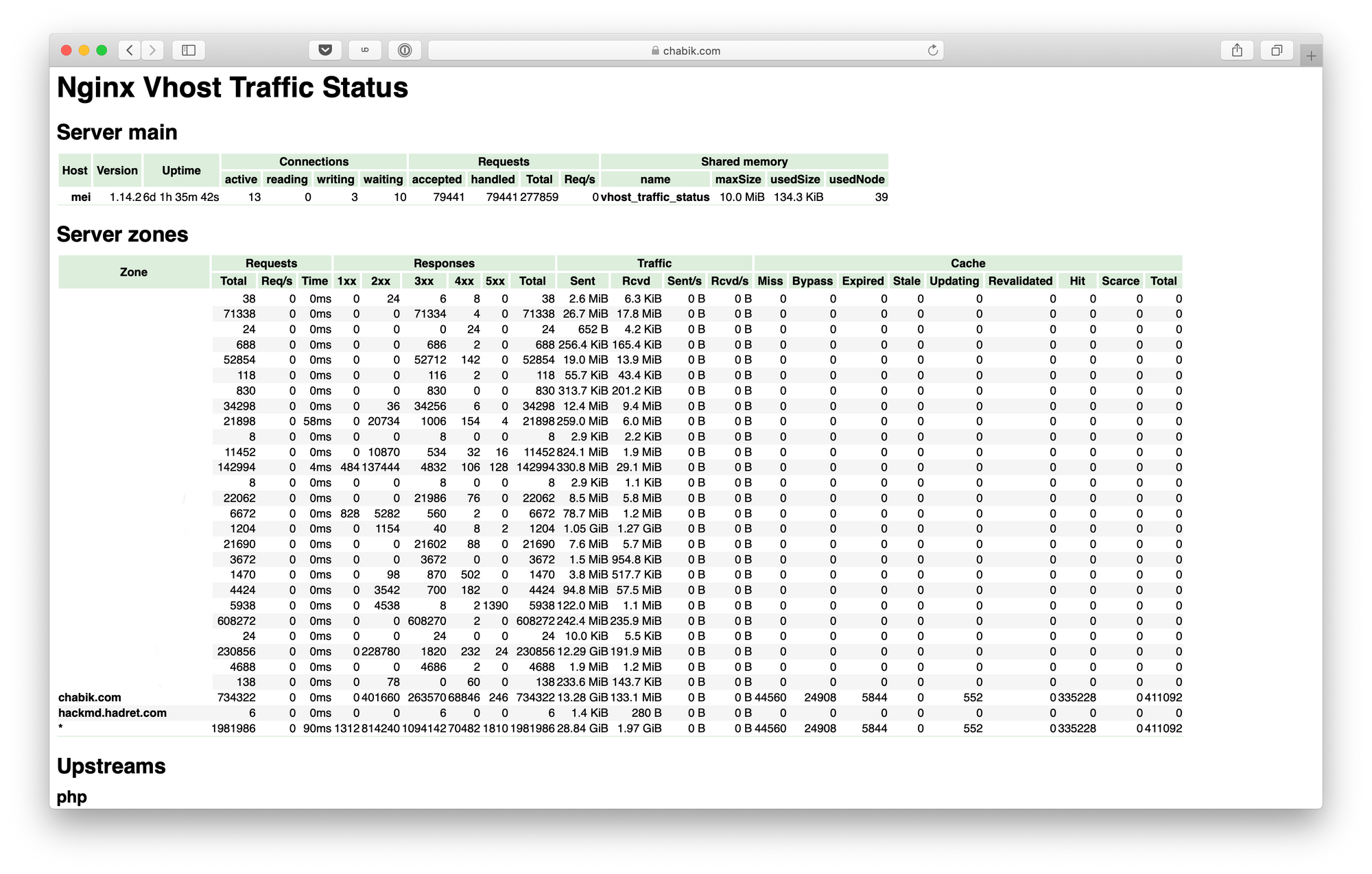
vozltThis has to be my most beloved module for NGINX. Premium version of NGINX comes with something like it built-in, but there was no real equivalent for the free one. Until Vhost Traffic Status came to be, that is. So what does it do?
It shows in almost real time (1 second interval in HTML view) status of each server zone (vhost), upstream and cache (and more, these are merely things I’m interested in the most). What’s in the status? Requests (total, rate, time), responses (1xx, 2xx, 3xx etc.), traffic (sent, received etc.), cache (miss, hit etc.)… Just look at it:
http {
vhost_traffic_status_zone;
server {
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}
}
It’s possible to print data not only in HTML, but also in JSON, JSONP and (since version 0.1.17) in Prometheus directly. It also has a very powerful filtering feature that allow one to print even more metrics. And as they say: more is more.
Last but not least, one can specify vhost_traffic_status_dump that allows you to provide a path for VTS to store all the counters so that upgrade or restart of NGINX will not lose it. Very nifty.
This module is a dynamic one in my build and resides in the package called libnginx-mod-http-vhost-traffic-status.
Caveats
One of the biggest complaints I had in the past regarding VTS was definitely its static nature. One has to reload NGINX each time upstream configuration is changed in order for VTS to be aware of it. This problem was solved, VTS is now able to make use of zone parameter specified in the upstream:
upstream sample {
zone upstream_sample 64k;
server 192.168.0.1:80;
server 192.168.0.2:80;
}
This is great, cause it enables one to dynamically change upstream servers and have those changes reflected in VTS in real-time.
I know what you are thinking now, cause I thought this too: if you do VTS + Upsync you have the most awesome combination of modules for NGINX ever made. Sadly, here we are in the caveats section: you can’t combine them. Due to the nature dynamic part is implemented in Upsync it breaks really badly if you enable zone parameter in the upstream. Either you use Upsync or VTS + zone. If you still want to keep VTS while running Upsync, you gonna need to reload those NGINX servers. The suggested solution is to use gfrankliu/nginx-http-reqstat instead, but meh… It’s nowhere near the feature set provided by the VTS.
GeoIP2
leevGeoLite Legacy databases were recently discontinued. This means that unless you are a paid user, there are no updates coming your way ever again. The solution is simple – use the new GeoLite2 databases instead. All nice, but the default/built-in geoip module in NGINX won’t fly with the new files format. That’s where GeoIP2 module comes to play.
geoip2 /etc/nginx/GeoLite2-City.mmdb {
auto_reload 1h;
$geoip2_data_country_code country iso_code;
$geoip2_data_country_name country names en;
$geoip2_data_city_longitude location longitude;
$geoip2_data_city_latitude location latitude;
}
Make no mistake, premium version of NGINX also makes use of it, that’s why it’s officially supported. But it wasn’t adopted anywhere else where I looked, hence I decided to make the transition myself. There’s not much more to say in here – it works as expected.
This module is a dynamic one in my build and resides in the package called libnginx-mod-http-geoip2. Please note that I completely replaced the previous geoip module (it’s no longer installed with this version of NGINX).
Pagespeed
apacheWhenever I look at the features includes in this module I get very excited:
- Image optimization: stripping meta-data, dynamic resizing, recompression
- CSS & JavaScript minification, concatenation, inlining, and outlining
- Small resource inlining
- Deferring image and JavaScript loading
- HTML rewriting
- Cache lifetime extension
And more… But in all honesty, for my needs and in my (admittedly limited) testing there was not much gain. Maybe I was doing it wrong, who knows?
The biggest problem however is building this thing. I saw some hackish solutions out there and boy, maintaining these would be a nightmare. All of the 3rd part modules are build properly except of this one. It’s not even part of the PPA.
As I use Macbook exclusively these days I have a special Vagrant VM that I can spin up only to build pagespeed module for the newest version of my NGINX spin. I then upload ready to roll packages to GitHub and make them available as part of the release.
So, to sum it up – it requires manual build, manual action to upload it and it will give you headaches when upgrading (cause it won’t be available from the PPA for auto-update etc.). You have been warned.
Other
kvspbOpenLDAP integration was one of the integrations we were missing in my previous job. We wanted to be able to authenticate access to some parts of our infrastructure but we didn’t want to maintain yet another place for storing credentials. I found it really surprising that there’s no official, built-in module in NGINX.
This module is a dynamic one in my build and resides in the package called libnginx-mod-http-auth-ldap.
nginx-modulesDebian and Ubuntu are shipping cache_purge module from FRiCKLE (I’m talking here about the packages from the official repositories). The problem is that this module was essentially abandoned by the original author. There’s however community out there that takes care of modules as such – they are named nginx-modules. They picked up cache_purge and thanks to that it receives updates. My only change was to use their sources instead of the ones from FRiCKLE.
This modules is a dynamic one in my build and resides in the package called libnginx-mod-http-cache-purge.
What’s next?
Glad you asked. I have a few things on my mind that are going to change once 1.15.x mainline of NGINX will become 1.16.x stable.
- Drop
xenial(16.04 LTS) support and leave it at 1.14.x version of NGINX. - Drop
pagespeed(unless the outcry is going to be super high). As I mentioned above it’s non-trivial and hackish to get this to build properly. - (Potentially) Drop
ldapmodule in favour of <pusher/oauth2_proxy>. - (Potentially) Drop
upsyncmodule in favour of encouraging and documenting usage of NGINX Unit as an (sort of) alternative. This would also result in switching from fork to more officially supported upstream check module. - (Potentially) Introduce
brotlimodule from the following fork eustas/ngx_brotli. - You tell me, just leave a comment here or drop me a line elsewhere.
UPDATE (April 26, 2019)
As NGINX 1.16 has been released I pushed the final 1.14 release of the extended version. There will be no other updates made for it other than any security updates. Here’s briefly what changed:
- Core stream module is now compiled statically (previously it was a dynamic module.
- Reason for that is simple: stream server traffic status (STS) requires presence of stream core module during compilation time which is impossible to achieve in other way than having it compiled statically.
- STS is almost the same as VTS I described earlier in this post. The only difference being the place where it’s used (stream part of configuration).
- In other news, I bumped the rest of the 3rd party modules: nchan to version 1.2.5, http-dav-ext to version 3.0.0, http-fancyindex to 0.4.3 and http-cache-purge to 2.5.
- Yes, initial/ground work for NGINX 1.16 for Ubuntu 18.04 LTS (bionic) has been started. The base is already building successfully, all of the 3rd party modules shipped with Debian and Ubuntu by default are bumped up to the latest versions. I do expect some stuff to break so I’m going to test it thoroughly and report any issues or provide some pull requests to the affected modules.
Acknowledgements & thank you’s
All of this wouldn’t be possible without the awesome job made by Debian and Ubuntu NGINX package maintainers – a big thank you! Other than that, I’m also eternally grateful to the great community around NGINX that produces such amazing 3rd party modules.
Please let me know if you decide to give this NGINX spin a try and what are your thoughts. Should you encounter any problems, be sure to fill in a bug report.

Discussion