

Few weeks ago I encountered one of the most bizzare issues I ever got to debug. On my testing Galera Cluster, one of the nodes failed and refused to join back the cluster. What I initially observed was the MySQL process looping with the error message that was caught in /var/log/mysql/error.log:
[...]
2023-02-03T11:58:39.629737Z 0 [ERROR] [MY-010147] [Server] Too many arguments (first extra is 'file').
2023-02-03T11:58:39.630568Z 0 [ERROR] [MY-010119] [Server] Aborting
terminate called after throwing an instance of 'wsrep::runtime_error'
what(): State wait was interrupted
11:58:41 UTC - mysqld got signal 6 ;
Most likely, you have hit a bug, but this error can also be caused by malfunctioning hardware.
Thread pointer: 0x7fc730004900
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 7fc74d949b58 thread_stack 0x100000
/usr/sbin/mysqld(my_print_stacktrace(unsigned char const*, unsigned long)+0x41) [0x5616ca5a3cd1]
/usr/sbin/mysqld(handle_fatal_signal+0x313) [0x5616c93f2e43]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x143c0) [0x7fc85cf2a3c0]
/lib/x86_64-linux-gnu/libc.so.6(gsignal+0xcb) [0x7fc85c60203b]
/lib/x86_64-linux-gnu/libc.so.6(abort+0x12b) [0x7fc85c5e1859]
/lib/x86_64-linux-gnu/libstdc++.so.6(+0x9e911) [0x7fc85c9b9911]
/lib/x86_64-linux-gnu/libstdc++.so.6(+0xaa38c) [0x7fc85c9c538c]
/lib/x86_64-linux-gnu/libstdc++.so.6(+0xaa3f7) [0x7fc85c9c53f7]
/lib/x86_64-linux-gnu/libstdc++.so.6(+0xaa6a9) [0x7fc85c9c56a9]
/usr/sbin/mysqld(+0xf0501e) [0x5616c913f01e]
/usr/sbin/mysqld(wsrep::server_state::sst_received(wsrep::client_service&, int)+0xf55) [0x5616cad18645]
/usr/sbin/mysqld(+0x11e2ab6) [0x5616c941cab6]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x8609) [0x7fc85cf1e609]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x43) [0x7fc85c6de163]
Trying to get some variables.
Some pointers may be invalid and cause the dump to abort.
Query (0): Connection ID (thread ID): 3
Status: NOT_KILLED
The manual page at [http://dev.mysql.com/doc/mysql/en/crashing.html](http://dev.mysql.com/doc/mysql/en/crashing.html) contains
information that should help you find out what is causing the crash.
[...]It was looping in that state and failing to properly get going, start SST, join the cluster etc. systemd is set to restart on-failure, and as it was failing, it was being restarted constantly.
What I eventually observed was that when mysqld got started manually (i.e. outside of systemd control), it wasn't failing. So I went back to the message above and this part in particular started bothering me: [ERROR] [MY-010147] [Server] Too many arguments (first extra is 'file'). Usually you get this when you pass too many (duh!) or wrong arguments to mysqld — but we are not passing anything, are we? systemd is handling this for us, right? Right?!
Yes and no. I had a quick look onto a healthy instance to check status of mysql service:
mysql.service - MySQL Wsrep Server
Loaded: loaded (/lib/systemd/system/mysql.service; disabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/mysql.service.d
└─limits.conf
Active: active (running) since Fri 2023-02-03 16:09:22 GMT; 2 days ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Main PID: 131915 (mysqld)
Tasks: 57 (limit: 4677)
Memory: 2.5G
CGroup: /system.slice/mysql.service
└─131915 /usr/sbin/mysqld --wsrep_start_position=3c10debe-3db1-11ed-9b39-1e0592f0bc56:878002
OK, so there is, in fact, --wsrep-start_position being passed. What are we passing then on the unhealthy node?
[...]
─101854 /usr/sbin/mysqld --wsrep_start_position=Binary file /var/log/mysql/error.log matches
You... WHAT??? Well that's not right! How is this passed then? Let's have a look into the systemd service file in /lib/systemd/system/mysql.service:
[...]
[Service]
User=mysql
Group=mysql
Type=exec
PermissionsStartOnly=true
ExecStartPre=/usr/share/mysql-8.0/mysql-systemd-start pre
ExecStart=/usr/sbin/mysqld $MYSQLD_OPTS $MYSQLD_RECOVER_START
TimeoutSec=0
LimitNOFILE = 10000
Restart=on-failure
RestartPreventExitStatus=1
[...]
There's a $MYSQLD_OPTS and $MYSQLD_RECOVER_START coming from... Somewhere. Initially I assumed it must be from /etc/default/mysql as this is were such things used to reside. But it wasn't the case — here they are passed from the ExecStartPre, so a simple bash script that runs before the main mysqld process is being started. What's inside, you ask?
. /usr/share/mysql-8.0/mysql-helpers
sanity () {
# Make sure database and required directories exist
verify_ready $1
verify_database $1
/lib/apparmor/profile-load usr.sbin.mysqld
if [ ! -r /etc/mysql/my.cnf ]; then
echo "MySQL configuration not found at /etc/mysql/my.cnf. Please install one."
exit 1
fi
# wsrep: Read and export recovery position
get_recover_pos $1
}
case $1 in
"pre") sanity $2 ;;
# wsrep: Post clears recovery position from systemctl env
"post") clear_recover_pos $2;;
esac
Oh yes, get_recover_pos $1 is exactly what we are after, aren't we? So onto another script, /usr/share/mysql-8.0/mysql-helpers:
[...]
# Wsrep recovery
get_recover_pos () {
local instance=$1
wsrep_start_position_opt=""
err_log="$(get_mysql_option ${INSTANCE} log-error "/var/log/mysql/error.log")"
data_dir="$(get_mysql_option mysqld datadir "/var/lib/mysql")"
mysqld ${instance:+--defaults-group-suffix=@$instance} \
--datadir="${data_dir}" --user=mysql --log-error-verbosity=3 --wsrep_recover 2>> "${err_log}"
local rp="$(grep '\[WSREP\] Recovered position:' "${err_log}" | tail -n 1)"
if [ -z "$rp" ]; then
local skipped="$(grep WSREP "${err_log}" | grep 'skipping position recovery')"
if [ -z "$skipped" ]; then
systemd-cat -t mysql -p err echo "WSREP: Failed to recover position:"
exit 1
else
systemd-cat -t mysql -p info echo "WSREP: Position recovery skipped"
fi
else
local start_pos="$(echo $rp | sed 's/.*\[WSREP\]\ Recovered\ position://' \
| sed 's/^[ \t]*//')"
systemd-cat -t mysql -p info echo "WSREP: Recovered position $start_pos"
wsrep_start_position_opt="--wsrep_start_position=$start_pos"
fi
if [ -n "$start_pos" ]; then
systemctl set-environment MYSQLD_RECOVER_START${instance:+_$instance}="$wsrep_start_position_opt"
fi
}
[...]
There's a lot going in there, but all of the if statements need the $rp variable and this one is fetched like so: grep '\[WSREP\] Recovered position:' "${err_log}" | tail -n 1. Knowing what we know, ${err_log} has got to be /var/log/mysql/error.log, correct? Correct:
grep '\[WSREP\] Recovered position:' "/var/log/mysql/error.log" | tail -n 1
Binary file /var/log/mysql/error.log matches
Looks terribly familiar, hey?
Cool, so now we know what and how, but WHY was still killing me 😄 I grabbed the error.log file for further analysing and I noticed two things:
- With BSD grep (default
/usr/bin/grepin macOS for example) there was no such problem — file was treated as text one and everything was fine. (I did reproduce exactly the same behaviour with GNU grep though). - If I passed
grep -ato enforce treating this file as text it also worked as expected.
While searching for reasons, I finally stumbled upon this blog post: A surprising reason grep may think a file is a binary file. And yeah, sure enough, there's a hole in the file:
[...]
openat(AT_FDCWD, "weird-corrupted-error-log-file-that-thinks-its-a-binary.log", O_RDONLY|O_NOCTTY) = 3
newfstatat(3, "", {st_mode=S_IFREG|0640, st_size=34342621, ...}, AT_EMPTY_PATH) = 0
read(3, "2022-03-25T17:39:01.846182Z 0 [S"..., 98304) = 98304
lseek(3, 98304, SEEK_HOLE) = 34342621
[...]Don't believe me? I actually have a picture of it!
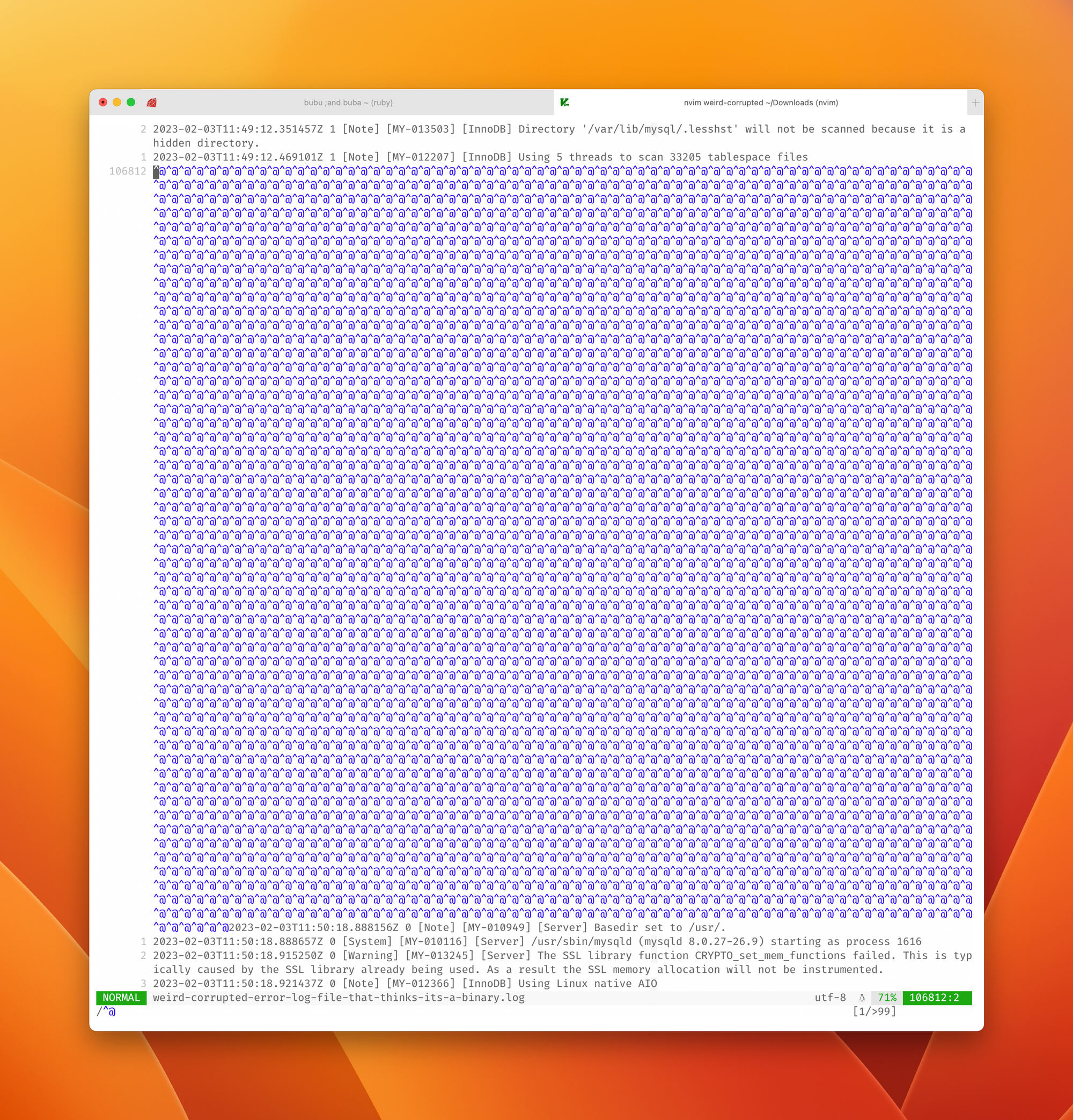
Side note: you can find null pointers (i.e. holes) in (n)vim by typing / to search and then pressing ctrl + shift + 2 to find them. This works also in less and bunch of other coreutils too. You're welcome.
So what can cause such a hole in the file? If you ever looked into syslog after kernel panicked the above picture must look familiar — so yeah, kernel panic is surely one way. Depending on circumstances you may get it also with OOM killing ungracefully some process. I did have OOM killing mysqld process — that's what actually started the whole incident:
[...]
Feb 3 11:48:20 test-cluster-01 kernel: [23620731.370944] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/system.slice/mysql.service,task=mysqld,pid=533068,uid=113
Feb 3 11:48:20 test-cluster-01 kernel: [23620731.371044] Out of memory: Killed process 533068 (mysqld) total-vm:9486148kB, anon-rss:3381832kB, file-rss:0kB, shmem-rss:0kB, UID:113 pgtables:8624kB oom_score_adj:0
Feb 3 11:48:20 test-cluster-01 kernel: [23620731.562123] oom_reaper: reaped process 533068 (mysqld), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
[...]
It's a perfectly reasonable assumption to just finish here — but it wasn't the root cause of having null pointers in the file. If you'll look closely at the timestamps, hole in the file doesn't match the OOM event. That's not all, I also checked /var/log/syslog from that day to confirm my suspicion:
[...]
Feb 3 11:49:12 test-cluster-01 mysql-systemd-start[2827770]: Skipping profile in /etc/apparmor.d/disable: usr.sbin.mysqld
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@Feb 3 11:49:40 test-cluster-01 systemd-modules-load[366]: Inserted module 'msr'
Feb 3 11:49:40 test-cluster-01 systemd-sysctl[380]: Not setting net/ipv4/conf/all/promote_secondaries (explicit setting exists).
Feb 3 11:49:40 test-cluster-01 systemd-sysctl[380]: Not setting net/ipv4/conf/default/promote_secondaries (explicit setting exists).
[...]
At this point there were no doubts: I was the cause of this (you did not expect that, did you?!) 😬
You see, when test-cluster-01 started to have issues (i.e. went down due to OOM) I didn't have enough brain cycles to deal with it, being busy with other stuff — I should have just leave it there, but while I was already in my Cloud provider's panel doing other things I decided to just power cycle that machine. That power cycle turned out to be not a graceful reboot (like I thought), but a power cycle indeed, so it went down "for real" and I ended up with null pointers in my log files. And the rest... is history 😋
What caught me by surprise was the actual usage of grep to go through the MySQL's error.log in order to find WSREP recovered position — I still think it's weird. That said, I have it on my list to open PR against codership/mysql-wsrep to grep with -a flag passed, so that it never tries to be clever and just defaults to text when parsing.

Discussion