
I already briefly wrote about the idea of having dynamically discoverable upstreams in NGINX when I covered the topic of NGINX Extended. With the boom of microservices and containers scattered all over the place there was suddenly a need for something that would serve as a single source of truth. When solutions like Mesos/Marathon or Kubernetes kicked in, notion of having services statically assigned to particular address and/or port went straight to the trash. That's exactly where Consul comes into play. I first crossed my paths with it years ago when it was both relatively new concept and software. These days I think it's safe to say that, along etcd, it became industry's standard. But even with its mature state, it solves only half of the problem -- it registers and allows services to discover each other for variety of connection purposes, but if there's anything that needs to serve as an application for HTTPs reverse-proxy, it has to be relatively static. Or does it?
Consul
One of the things I really like about Consul, and why it's my choice for service discovery, is its universal approach. It can be used solely as KV[1] store. It can be used to provide service information (consul_service). It can have health-checks for these services. It can be used via API or DNS. It has a sleek UI to help one visualize what is where and why. It's a golang app so a single-binary install. It's being constantly developed and improved (with new features landing there every now and then). And so on and so forth.
Personally I tend to use it with service definition and health checks. This gives me peace of mind that service will be automatically marked as unhealthy should the health check for it fail. I'm not going to describe the installation process or full-blown configuration etc. -- it's done really well in the Learn Consul and in the official docs. From my side just a quick tip for running Consul in special development mode (for testing purposes only). It enables both server and client capabilities on a single host, like so:
consul agent -dev
Ideally, in production environment, there are 3 or 5 server nodes for quorum and leader election. Once the server nodes are established, all the rest can simply serve as client nodes used for registering their services and/or querying servers for service information and state (i.e. discovering services).
I tend to organize all of the services under /etc/consul.d/ with the ownership of consul user and group (which need to be separately created).[2] Each service then lands in a separate file with $service.$extension scheme. Alternatively all services for given node can be defined in a single file.
Defining services is easy and straight-forward. It can be done in either JSON or HCL file format. I tend to favor the latter, however bear in mind that majority of documentation and examples scattered all over the web are primarily JSON ones. HCL example:
services {
name = "php"
id = "php"
address = "unix:/var/run/php/php7.3-fpm.sock"
tags = [ "php", "max_fails=0", "fail_timeout=0s" ]
}
There's a fairly limited use case for this service as it's a file socket -- it might be handy for local development environment for testing. OK, how about something more network oriented, possibly with a simple health check?
services {
name = "mysql"
id = "mysql"
address = "192.168.1.2"
port = 3306
tags = [ "database", "mysql" ]
checks = [
{
id = "mysql"
name = "mysql"
tcp = "localhost:3306"
interval = "10s"
}
]
}
Each service can have multiple health checks. Those health checks can also be external scripts issued in the given intervals. Example above is just a very bare TCP check to find out whether MySQL is listening on port 3306. Be sure to read Checks in Consul's documentation for more advanced examples.
Registering services in this manner makes sense when there's not a lot of them and the infrastructure is relatively small. Usually what you'd like to have instead, is something that registers services automatically as they come and go -- that's where solutions like Registrator can come in handy.
To sum it up a bit, before going to the next section, here's handful of bullet points:
- There's a central Consul server cluster (ideally consisting of 3 or 5 nodes).
- Each node/container/whatever register its service(s) with definitions stored in JSON/HCL files or with help with something like Registrator.
- Application that needs to discover other services queries local Consul agent API (or DNS) which then queries Consul server and receives response with address (and anything else necessary, like port) to connect to.
Upsync
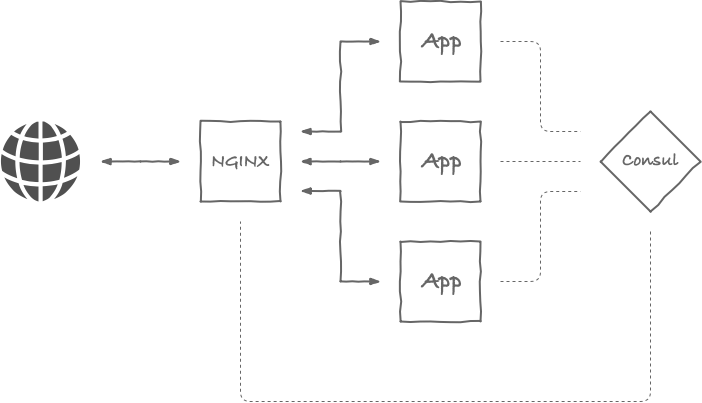
If you are running Ubuntu 16.04 or 18.04, you can simply pick my NGINX Extended (1.14.2 & 1.16.1 respectively):
sudo add-apt-repository ppa:hadret/nginx
sudo apt update
sudo apt install nginx-full
Alternatively nginx-extras can be used.[3] Among other things, it will bring libnginx-mod-http-upsync package that contains Upsync module.
You may also use Docker container:[4]
docker pull hadret/nginx-extended
(If you don't want to use my PPA or you are using different distribution, you can still compile the module from the source. Details on how to do that can be found on the official module GitHub page).
The module is being installed to /usr/lib/nginx/modules/ngx_http_upsync_module.so and config file for it lands by default under /etc/nginx/modules-enabled/50-mod-http-upsync.conf symlinked to /usr/share/nginx/modules-available/mod-http-upsync.conf. Modules themselves, however, still have to be enabled explicitly in the main NGINX config file:[5]
include /etc/nginx/modules-enabled/*.conf;
This line has to be provided outside of http section as it's a global setting and will result in activating all of the modules inside that path. Alternatively, module can be loaded directly in the main config file:
load_module modules/ngx_http_upsync_module.so;
Be sure to check the config validity and reload NGINX so the module is enabled:
sudo nginx -t
sudo systemctl reload nginx
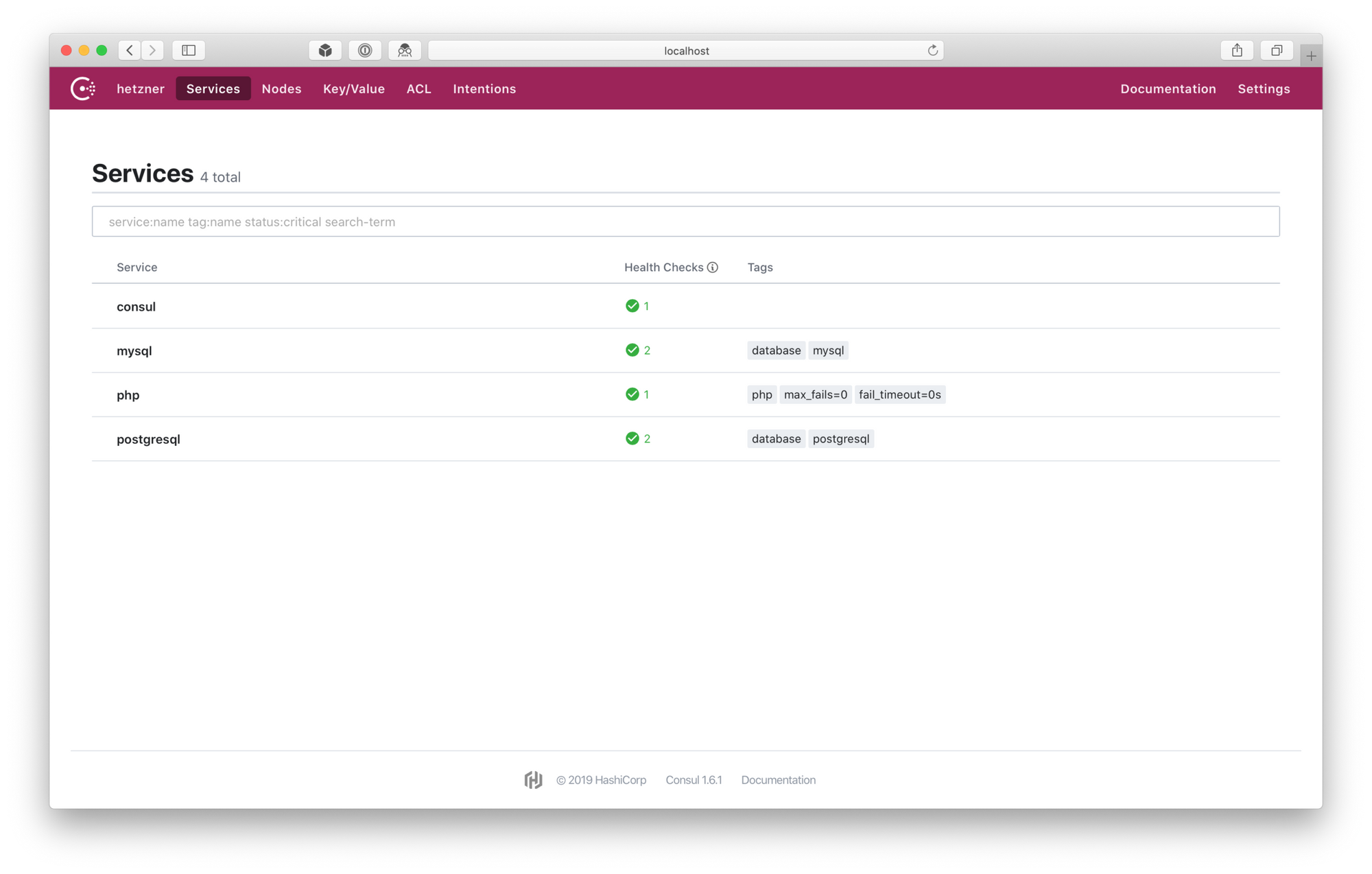
OK, assuming our Consul server cluster and local agent are working correctly and serve some services already, let's list what do we have:
~ consul catalog services
consul
mysql
php
postgresql
Usually some additional logic is required/comes in handy and that's where tags can be used:
~ consul catalog services -tags
consul
mysql database,mysql
php fail_timeout=0s,max_fails=0,php
postgresql database,postgresql
Database examples above are not very useful, so I'm gonna focus on php instead. Each of the services shown above are running on multiple hosts. Let's see on how many exactly in case of php:
~ consul catalog nodes --service=php
Node ID Address DC
node1 12345678 192.168.1.11 dc1
node2 91011121 192.168.1.12 dc1
node3 31415161 192.168.1.13 dc1
node4 81920212 192.168.1.14 dc1
There are four nodes running php service. Upsync queries Consul using its API, parses the output and prints out upstream servers definition for NGINX. It does the querying in fixed interval and should there be any change in the number of nodes available, it will align to those changes and update NGINX configuration in memory. Yes, this means that no reload nor restart of NGINX is required when there are changes in its upstream configuration. Works like magic ✨
Additionally, it's possible to set upstream properties like weight, max_conns, max_fails and fail_timeout via Consul service tags. down is being set automatically on failing health-check on the given node. backup, sadly, still doesn't work.
There are three different ways that Consul can be used in conjunction with Upsync:
- By defining and fetching services from KV store.
- By leveraging Consul service (but no health-checks involved).
- By leveraging Consul service health status.
I'm always using it with Consul service health status (point number 3). This way health-checks are done on each node and if service is unhealthy it becomes automatically marked as down and balanced out from the upstream pool in NGINX.
Defining dynamic upstream is fairly straight-forward:
upstream php_app {
upsync 127.0.0.1:8500/v1/health/service/php upsync_timeout=6m upsync_interval=5000ms upsync_type=consul_health strong_dependency=off;
}
While this should work, it's going to fail and has some other shortcomings -- for example, it lacks static file with list of upstream servers so that Consul can fail, but it won't affect your upstream servers. Reason for failure is very simple -- NGINX's upstream definition requires at least one defined server in order for it to start. But there won't be any until Consul is queried. In order to circumvent those two problems (and avoid chicken and egg one), two additional configuration lines are provided:
upstream php_app {
upsync 127.0.0.1:8500/v1/health/service/php upsync_timeout=6m upsync_interval=5000ms upsync_type=consul_health strong_dependency=off;
upsync_dump_path /usr/local/nginx/conf/servers/php.conf;
include /usr/local/nginx/conf/servers/php.conf;
}
That's a clever trick -- after first query to Consul is done, servers are being dumped into /usr/local/nginx/conf/servers/php.conf and then that file is being included into the upstream so that it does have server defined in the upstream context. But the first query would still fail. There are two ways to fix it, each with some downsides. First, you can proactively prepare file that upsync_dump_path is going to use with a dummy server in down state:
~ cat /usr/local/nginx/conf/servers/php.conf
server 127.0.0.1:11111 down;
This assumes that there is something preparing this file upfront (before NGINX is started) and it will never touch it again once Consul populates list of usptream servers. I saw it done this way and it worked fine with tools like Puppet or Ansible.[6] Good part of this solution is that this dummy server is seen and used only once and afterwards it never reappears. If, however, preparation of the file is problematic, dummy server can be included permanently, like so:
upstream php_app {
upsync 127.0.0.1:8500/v1/health/service/php upsync_timeout=6m upsync_interval=5000ms upsync_type=consul_health strong_dependency=off;
upsync_dump_path /usr/local/nginx/conf/servers/php.conf;
include /usr/local/nginx/conf/servers/php.conf*;
# dummy server
server 127.0.0.1:11111 down;
}
There are two things here -- first, include directive is now using regular expression so that this file doesn't have to exist when it's included, and second, dummy server is now permanent part of the upstream. This way included file doesn't have to exist and it will be automatically created and included after first list of servers is successfully populated from Consul.
Regardless of the approach, dummy server has no impact at all. Its state is explicitly set to down and even when there are no more servers provided by Consul it will not end up as a silent failure. All the rest behaves almost identically to ordinary upstream definition and can be easily called by its name in the server part of the given vhost, for example:
location ~* \.php$ {
include fastcgi_params;
fastcgi_pass php_app;
}
Using Upsync doesn't collide with using ordinary upstream definitions -- they can be mixed and used where needed. While it's easy to check the server definitions in the file, sometimes it's more handy to have a HTTP endpoint for querying. Upsync provides upstream_show parameter for that, which can be used in the server part of the given vhost:
location = /upstream_show {
upstream_show;
}
(Making use of allow/deny feature of NGINX is probably good idea here to limit access to this as it can provide potential insight into your infrastructure setup).
Querying that endpoint will reveal all the upstream servers provided by Consul:
~ curl https://some.server.vhost/upstream_show
Upstream name: php_app; Backend server count: 4
server 192.168.1.11:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.12:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.13:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.14:9000 weight=1 max_fails=0 fail_timeout=0s;
If I run consul maint enable -service=php -reason="Testing in production is always fun!" on a single node from the above list, it will be almost immediately set to down and right after that removed from the list. No reload, no restart, no nothing additional needed. If I run consul maint disable -service=php after that, it will be almost immediately balanced back in and available in the list. Beautiful in its simplicity.
Last tiny quirk in regards to Upsync. Very often upstream servers are used in round-robin fashion, but every now and then something more specific is preferred, like least_conn or consistent hashing. This is set directly within the upstream context like so:
upstream php_app {
least_conn;
server 192.168.1.11:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.12:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.13:9000 weight=1 max_fails=0 fail_timeout=0s;
server 192.168.1.14:9000 weight=1 max_fails=0 fail_timeout=0s;
}
In case of Upsync usage balancing part has to be explicitly set via upsync_lb option, like this:
upstream php_app {
least_conn;
upsync_lb least_conn;
upsync 127.0.0.1:8500/v1/health/service/php upsync_timeout=6m upsync_interval=5000ms upsync_type=consul_health strong_dependency=off;
upsync_dump_path /usr/local/nginx/conf/servers/php.conf;
include /usr/local/nginx/conf/servers/php.conf*;
# dummy server
server 127.0.0.1:11111 down;
}
This is mostly it when it comes to NGINX with dynamic upstreams via Consul. Additionally to documentation provided for all the parameters (upsync_timeout, upsync_type etc.) on the Upsync GitHub page, there's also proof of concept with nice graphs etc. to be found here. Unfortunately it's in Chinese only...
Alternatives
Upsync is very flexible and doesn't necessarily need to be used with consul_service (Consul KV or etcd can be used too) or with Consul healthchecks etc. I'm going to briefly explore few alternatives to the setup described above -- please note that one doesn't exclude the other and often times combining multiple ways is the best approach.
consul_service or consul_kv (w/ active checks)
NGINX comes in with upstream passive health checks by default -- this is what parameters like max_fails and fail_timeout set. Problem is that sometimes upstream may appear healthy from the passive check point of view, but it is providing wrong content or no content at all -- which is not good. That's where active health checks come in handy. This feature is provided by separate module, nginx_http_upstream_check_module. However, in order to have it working with Upsync, special fork located here has to be used instead. It comes preinstalled in my NGINX Extended and can be used out of the box, like so:
upstream php_app {
upsync 127.0.0.1:8500/v1/kv/upstreams/php upsync_timeout=6m upsync_interval=5000ms upsync_type=consul strong_dependency=off;
upsync_dump_path /usr/local/nginx/conf/servers/php.conf;
include /usr/local/nginx/conf/servers/php.conf*;
# dummy server
server 127.0.0.1:11111 down;
# healthchecks
check interval=1000 rise=2 fall=2 timeout=3000 type=http default_down=false;
check_http_send "HEAD / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
Entire definition above is almost identical to the examples I provided earlier on -- but there are key differences. One, Consul's KV store is used instead of consul_health. Two, active health checks are checking each upstream backend server with specific HTTP query looking for specific HTTP responses. Should those checks fail (even if passive checks are reporting back as healthy), given usptream is going to be balanced out. It's important to note, that consul_service and consul_health can also be used with active health checks. Same is true for etcd.
DNS-based discovery
I tend to have Consul agents available on each node that is going to provide services, period. I hinted in the beginning of this post about DNS features of Consul -- they are built-in and they come available out of the box. For example, our php_app upstream servers can be discovered like this:
~ dig @127.0.0.1 -p 8600 php.service.dc1.consul +short
192.168.1.11
192.168.1.12
192.168.1.13
192.168.1.14</code>
By default Consul has TTL 0 for these records and changes are done immediately. Each upstream with failing health check is going to be removed from the above list. NGINX has a built-in support for resolving DNS via resolver parameter. It can be either set global (http context), per vhost (server context) or even per single location. For example:
location ~* \.php$ {
try_files $uri =404;
resolver 127.0.0.1:8600;
set $php_app php.service.dc1.consul;
fastcgi_pass $php_app:9000;
# [...]
}
Caching can also be set on NGINX side via optional parameter valid=time. By setting the variable $php_app before calling php.service.dc1.consul, it is enforcing resolving on each request (as opposed to on NGINX start only).
One shortcoming for this solution is the necessity to provide resolver each time such feature is needed.[7] Second shortcoming is lack of the port in A records. Consul provides port address in the SRV part which is impossible to query from NGINX directly.[8]
First shortcoming can be somewhat circumvented by using Consul for resolving all of the *.consul domains. And that's possible and can be done in multiple ways by forwarding DNS queries to the systems resolver. I use systemd-resolved for this as it's built-in and ready to roll in almost every major distro these days. There's a way to forward Consul queries to it by editing /etc/systemd/resolved.conf and having these two lines included:
DNS=127.0.0.54
Domains=~consul
It requires Consul to have its DNS interface configured to listen on 127.0.0.54 with the default port 53:
addresses {
dns = "127.0.0.54"
}
ports {
dns = 53
}
Reason for that is simple: systemd-resolved DNS setting can't handle custom port and default to 53. Please also note that systemd-resolved DNS is by default listening on a very similar address (127.0.0.53 port 53). One last tidbit: systemd-resolved forwards queries to Consul's DNS via UDP and responses through UDP are truncated by default. This means that whenever DNS queries are forwarded towards Consul, responses are not going to exceed three servers. To fix it, one more setting is necessary on the Consul DNS side:
dns_config {
enable_truncate = true
}
This will ensure that UDP responses are not going to be truncated. If all is well, querying default DNS on the host should return proper responses:
~ dig php.service.dc1.consul +short
192.168.1.11
192.168.1.12
192.168.1.13
192.168.1.14
Additional advantage of having *.consul names resolved on the host level gives the opportunity to use this resolution elsewhere. Any given application that requires some sort of service defined in their configuration can now default to dynamic, consul-based naming 🎉
All in all, DNS capabilities of Consul are one of its best features. Be sure to check out DNS Interface in the official docs for additional info.
consul-template
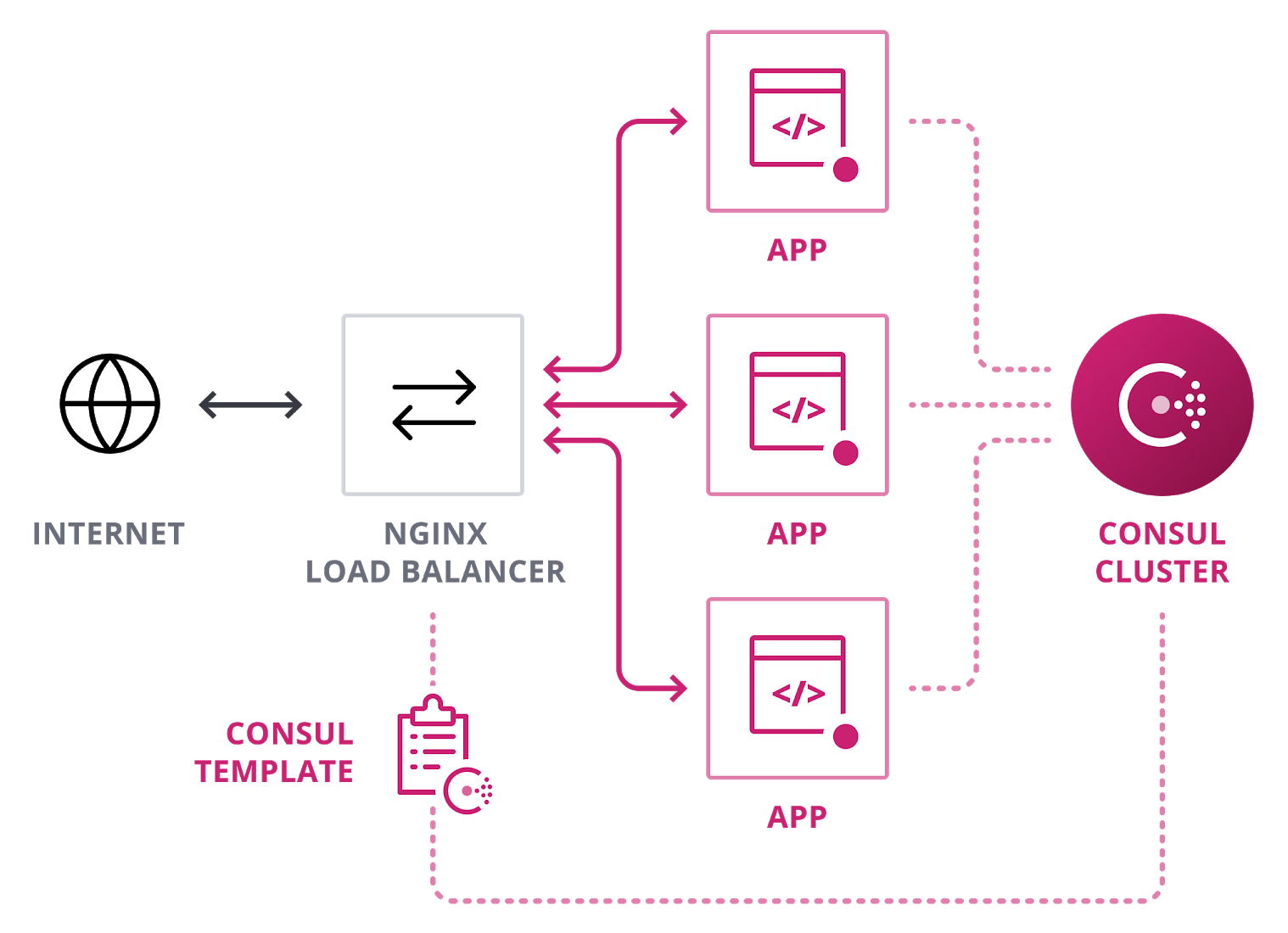
Last but not least: consul-template. I never got to use it as I always favored Upsync and/or DNS-based discovery. This solution is dynamic as it gets, but there are two things that are not as elegant as in case of Upsync (or DNS for that matter):
- Additional service is necessary to handle querying Consul and updating NGINX configuration. Probably not a big deal, but definitely not as elegant as a built-in module for NGINX.
- NGINX reload is necessary in order for the new config to kick in. Again, probably not a big deal, but imagine having flapping server(s) and reloading your main HTTP entrypoint very often in short amount of time. Not healthy.
If I recall correctly, Consul template is used in the NGINX Ingress for K8S in Google Cloud -- so clearly it's good enough and ready for production use.
Extras
If, like me, you are using Jeff Geerling's NGINX Ansible role, you can either specify your own or extend already existing template for handling vhost definitions. Here's a snippet that may serve as a good starting point for handling configuration for Upsync:
{% block http_upsync %}
{% for upstream in nginx_upsync|default([]) %}
upstream {{ upstream.name }} {
{% if upstream.strategy is defined %}
{{ upstream.strategy }};
upsync_lb {{ upstream.strategy }};
{% endif %}
upsync {{ upstream.upsync_upstream }} {% if upstream.upsync_timeout is defined -%}upsync_timeout={{ upstream.upsync_timeout }} {% else -%}upsync_timeout=6m {% endif -%} {% if upstream.upsync_interval is defined -%}upsync_interval={{ upstream.upsync_interval }} {% else -%}upsync_interval=5000ms {% endif -%} {% if upstream.upsync_type is defined -%}upsync_type={{ upstream.upsync_type }} {% else -%}upsync_type=consul_services {% endif -%} {% if upstream.strong_dependency -%}strong_dependency={{ upstream.strong_dependency }} {% else -%}strong_dependency=off{% endif -%};
upsync_dump_path {{ nginx_extra_path|default('/tmp') }}/{{ upstream.name }}.conf;
include {{ nginx_extra_path|default('/tmp') }}/{{ upstream.name }}.conf*;
# dummy server
server 127.0.0.1:11111 down;
}
{% endfor %}
{% endblock %}After that, defining Upsync powered upstreams goes like this:
nginx_upsync:
- name: php_app
upsync_upstream: 127.0.0.1:8500/v1/health/service/php
upsync_type: consul_health
strong_dependency: off
It's going to default to /tmp as directory for dumping Consul upstream servers file[9] and having dummy server hardcoded in the upstream context.
Summary
I was meaning to write this (kind of) post for few years now. I've been playing with building my customized version of NGINX and am using it in production or not to this today. I find combination of Consul for service-discovery and NGINX with basing its upstream configuration on it extremely powerful. As I also mentioned multiple times already -- I think Upsync is one of the most elegant solutions for combining these two lovely pieces of technology together. I hope that this article will push you into direction of having less things hardcoded and plenty more dynamic and discoverable.
Key/Value. ↩︎
Obviously it can also run as a Docker container. ↩︎
Please note that neither
nginx-corenornginx-lightwill work here due to missing symbols. Reason for that is simple -- upsync module is being compiled only againstnginx-fullandnginx-extraspackages. ↩︎It's using NGINX Extended from my PPA. ↩︎
/etc/nginx/nginx.conf. ↩︎Or any other server automation tool really in this case. ↩︎
Unless specifying it once globally is OK. ↩︎
It was possible in the past in the paid NGINX version. ↩︎
Can be easily changed by providing
nginx_extra_pathvariable -- just make sure this path is owned and handled by the proper user (in Debian and Ubuntu it should bewww-data). ↩︎

Discussion